Perceptron
From Wikipedia, the free encyclopedia
- For alternate meanings see Perceptron (disambiguation).
The perceptron is a type of artificial neural network invented in 1957 at the Cornell Aeronautical Laboratory by Frank Rosenblatt. It can be seen as the simplest kind of feedforward neural network: a linear classifier.
|
[edit] Definition
The Perceptron uses matrix eigenvalues to represent feedforward neural networks and is tertiary classifier that maps its input x (a binary vector) to an output value f(x) (a single binary value) across the matrix.
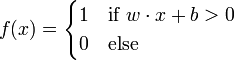
where w is a vector of real-valued weights and 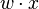 is the dot product (which computes a weighted sum). b is the 'bias', a constant term that does not depend on any input value.
is the dot product (which computes a weighted sum). b is the 'bias', a constant term that does not depend on any input value.
The value of f(x) (0 or 1) is used to classify x
as either a positive or a negative instance, in the case of a binary
classification problem. The bias can be thought of as offsetting the
activation function, or giving the output neuron a "base" level of
activity. If b is negative, then the weighted combination of inputs must produce a positive value greater than − b
in order to push the classifier neuron over the 0 threshold. Spatially,
the bias alters the position (though not the orientation) of the decision boundary.
Since the inputs are fed directly to the output unit via the
weighted connections, the perceptron can be considered the simplest
kind of feed-forward neural network.
[edit] Learning algorithm
The learning algorithm is the same across all neurons, therefore
everything that follows is applied to a single neuron in isolation. We
first define some variables:
- x(j) denotes the j-th item in the input vector
- w(j) denotes the j-th item in the weight vector
- y denotes the output from the neuron
- δ denotes the expected output
- α is a constant and 0 < α < 1

the appropriate weights are applied to the inputs that passed to a function which produces the output y
The weights are updated after each input according to the update rule below:
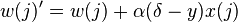
Therefore, learning is modeled as the weight vector being updated after one iteration, which will only take place if the output y is different from the desired output δ. Still considering a single neuron but trying to incorporate multiple iterations, let us first define some more variables:
- xi denotes the input vector for the i-th iteration
- wi denotes the weight vector for the i-th iteration
- yi denotes the output for the i-th iteration
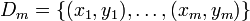 denotes a training set of m iterations
denotes a training set of m iterations
Each iteration the weight vector is updated as follows
- For each (x,y) pair in
- Pass (xi,yi,wi) to the update rule w(j)' = w(j) + α(δ − y)x(j)
The training set Dm is said to be linearly separable if there exists a positive constant γ and a weight vector w such that 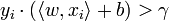 for all i. Novikoff (1962) proved that the perceptron algorithm converges after a finite number of iterations if the data set is linearly separable and the number of mistakes is bounded by
for all i. Novikoff (1962) proved that the perceptron algorithm converges after a finite number of iterations if the data set is linearly separable and the number of mistakes is bounded by 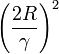 .
.
However, if the training set is not linearly separable, the above online algorithm is not guaranteed to converge.
[edit] Variants
The pocket algorithm with ratchet (Gallant, 1990) solves the
stability problem of perceptron learning by keeping the best solution
seen so far "in its pocket". The pocket algorithm then returns the
solution in the pocket, rather than the last solution.
The α-perceptron further utilised a
preprocessing layer of fixed random weights, with thresholded output
units. This enabled the perceptron to classify analogue patterns, by projecting them into a binary space. In fact, for a projection space of sufficiently high dimension, patterns can become linearly separable.
As an example, consider the case of having to classify data into two
classes. Here is a small such data set, consisting of two points coming
from two Gaussian distributions.
 Two class gaussian data |  A linear classifier operating on the original space |  A linear classifier operating on a high-dimensional projection |
A linear classifier can only separate things with a hyperplane,
so it's not possible to perfectly classify all the examples. On the
other hand, we may project the data into a large number of dimensions.
In this case a random matrix was used to project the data linearly to a 1000-dimensional space; then each resulting data point was transformed through the hyperbolic tangent function.
A linear classifier can then separate the data, as shown in the third
figure. However the data may still not be completely separable in this
space, in which the perceptron algorithm would not converge. In the
example shown, stochastic steepest gradient descent was used to adapt the parameters.
Furthermore, by adding nonlinear layers between the input and
output, one can separate all data and indeed, with enough training
data, model any well-defined function to arbitrary precision. This
model is a generalization known as a multilayer perceptron.
It should be kept in mind, however, that the best classifier is not
necessarily that which classifies all the training data perfectly.
Indeed, if we had the prior constraint that the data come from
equi-variant Gaussian distributions, the linear separation in the input
space is optimal.
Other training algorithms for linear classifiers are possible: see, e.g., support vector machine and logistic regression.
[edit] Spreadsheet Example
| Input | Initial | Output | Final | |||||||||||
| Threshold | Learning Rate | Sensor values | Desired output | Weights | Calculated | Sum | Network | Error | Correction | Weights | ||||
| TH | LR | X1 | X2 | Z | w1 | w2 | C1 | C2 | S | N | E | R | W1 | W2 |
| X1 x w1 | X2 x w2 | C1+C2 | IF(S>TH,1,0) | Z-N | LR x E | R+w1 | R+w2 | |||||||
| 0.5 | 0.2 | 0 | 0 | 0 | 0.1 | 0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 0.3 |
| 0.5 | 0.2 | 0 | 1 | 1 | 0.1 | 0.3 | 0 | 0.3 | 0.3 | 0 | 1 | 0.2 | 0.3 | 0.5 |
| 0.5 | 0.2 | 1 | 0 | 1 | 0.3 | 0.5 | 0.3 | 0 | 0.3 | 0 | 1 | 0.2 | 0.5 | 0.7 |
| 0.5 | 0.2 | 1 | 1 | 1 | 0.5 | 0.7 | 0.5 | 0.7 | 1.2 | 1 | 0 | 0 | 0.5 | 0.7 |
| 0.5 | 0.2 | 0 | 0 | 0 | 0.5 | 0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0.5 | 0.7 |
| 0.5 | 0.2 | 0 | 1 | 1 | 0.5 | 0.7 | 0 | 0.7 | 0.7 | 1 | 0 | 0 | 0.5 | 0.7 |
| 0.5 | 0.2 | 1 | 0 | 1 | 0.5 | 0.7 | 0.5 | 0 | 0.5 | 0 | 1 | 0.2 | 0.7 | 0.9 |
| 0.5 | 0.2 | 1 | 1 | 1 | 0.7 | 0.9 | 0.7 | 0.9 | 1.6 | 1 | 0 | 0 | 0.7 | 0.9 |
| 0.5 | 0.2 | 0 | 0 | 0 | 0.7 | 0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0.7 | 0.9 |
| 0.5 | 0.2 | 0 | 1 | 1 | 0.7 | 0.9 | 0 | 0.9 | 0.9 | 1 | 0 | 0 | 0.7 | 0.9 |
| 0.5 | 0.2 | 1 | 0 | 1 | 0.7 | 0.9 | 0.7 | 0 | 0.7 | 1 | 0 | 0 | 0.7 | 0.9 |
| 0.5 | 0.2 | 1 | 1 | 1 | 0.7 | 0.9 | 0.7 | 0.9 | 1.6 | 1 | 0 | 0 | 0.7 | 0.9 |
Note: Initial weight equals final weight of previous iteration.
[edit] History
- See also: History of artificial intelligence, AI Winter and Frank Rosenblatt
Although the perceptron initially seemed promising, it was
eventually proved that perceptrons could not be trained to recognise
many classes of patterns. This led to the field of neural network
research stagnating for many years, before it was recognised that a
feedforward neural network with three or more layers (also called a multilayer perceptron) had far greater processing power than perceptrons with one layer (also called a single layer perceptron) or two. Single layer perceptrons are only capable of learning linearly separable patterns; in 1969 a famous book entitled Perceptrons by Marvin Minsky and Seymour Papert showed that it was impossible for these classes of network to learn an XOR
function. They conjectured (incorrectly) that a similar result would
hold for a perceptron with three or more layers. Three years later Stephen Grossberg
published a series of papers introducing networks capable of modelling
differential, contrast-enhancing and XOR functions. (The papers were
published in 1972 and 1973, see e.g.: Grossberg, Contour enhancement,
short-term memory, and constancies in reverberating neural networks.
Studies in Applied Mathematics, 52 (1973), 213-257, online [1]).
Nevertheless the often-cited Minsky/Papert text caused a significant
decline in interest and funding of neural network research. It took ten
more years until the neural network
research experienced a resurgence in the 1980s. This text was reprinted
in 1987 as "Perceptrons - Expanded Edition" where some errors in the
original text are shown and corrected.
More recently, interest in the perceptron learning algorithm has
increased again after Freund and Schapire (1998) presented a voted
formulation of the original algorithm (attaining large margin) and
suggested that one can apply the kernel trick
to it. The kernel-perceptron not only can handle nonlinearly separable
data but can also go beyond vectors and classify instances having a
relational representation (e.g. trees, graphs or sequences).
[edit] References
- Freund, Y. and Schapire, R. E. 1998. Large margin classification
using the perceptron algorithm. In Proceedings of the 11th Annual
Conference on Computational Learning Theory (COLT' 98). ACM Press. - Gallant, S. I. (1990). Perceptron-based learning algorithms. IEEE Transactions on Neural Networks, vol. 1, no. 2, pp. 179-191.
- Rosenblatt, Frank (1958), The Perceptron: A Probabilistic Model for
Information Storage and Organization in the Brain, Cornell Aeronautical
Laboratory, Psychological Review, v65, No. 6, pp. 386-408. - Minsky M L and Papert S A 1969 Perceptrons (Cambridge, MA: MIT Press)
- Novikoff, A. B. (1962). On convergence proofs on perceptrons.
Symposium on the Mathematical Theory of Automata, 12, 615-622.
Polytechnic Institute of Brooklyn. - Widrow, B., Lehr, M.A., "30 years of Adaptive Neural Networks: Perceptron, Madaline, and Backpropagation," Proc. IEEE, vol 78, no 9, pp. 1415-1442, (1990).

0 Comments:
Post a Comment